クライアント/サーバーの最適化
4Dは、クライアント/サーバーアーキテクチャーにおいてエンティティセレクションを使用、あるいはエンティティを読み込む ORDAリクエストについて最適化する機構を提供しています。 この最適化機構は、ネットワーク間でやり取りされるデータの量を大幅に縮小させることで 4Dの実行速度を向上させます。 これには以下のような機能が含まれます: この最適化機構は、ネットワーク間でやり取りされるデータの量を大幅に縮小させることで 4Dの実行速度を向上させます。 これには以下のような機能が含まれます:
- 最適化コンテキスト
- ORDAキャッシュ
対応しているアーキテクチャー
最適化をサポートしている ORDAクライアント/サーバーアーキテクチャーは次のとおりです:
- 4Dリモートデスクトップアプリケーションによって
dsを介してアクセスされるサーバーデータストア Open datastoreを介してアクセスされる リモートデータストア (クライアントRESTリクエスト)
最適化コンテキスト
最適化コンテキストは、以下の実装に基づいています:
-
クライアントがサーバーに対してエンティティセレクションのリクエストを送ると、4D はコード実行の途中で、エンティティセレクションのどの属性がクライアント側で実際に使用されているかを自動的に "学習" し、それに対応した "最適化コンテキスト" をビルドします。 このコンテキストはエンティティセレクションに付随し、使用された属性を保存していきます。 他の属性があとで使用された場合には自動的に情報を更新していきます。 以下のメソッドや関数が学習のトリガーとなります:
-
サーバー上の同じエンティティセレクションに対してその後に送られたリクエストは、最適化コンテキストを再利用して、サーバーから必要な属性のみを取得していくことで、処理を速くします。 たとえば、エンティティセレクション型のリストボックス では、先頭行の表示中に学習がおこなわれます。 次の行からは、表示が最適化されます。 以下の関数は、ソースのエンティティセレクションの最適化コンテキストを、戻り値のエンティティセレクションに自動的に付与します:
-
既存の最適化コンテキストは、同じデータクラスの他のエンティティセレクションであればプロパティとして渡すことができるので、学習フェーズを省略して、アプリケーションをより速く実行することができます (以下の contextプロパティの使用 を参照してください)。
-
dataStore.setRemoteContextInfo()関数を使用して、最適化コンテキストを手動で構築することができます (コンテキストの事前設定 参照)。
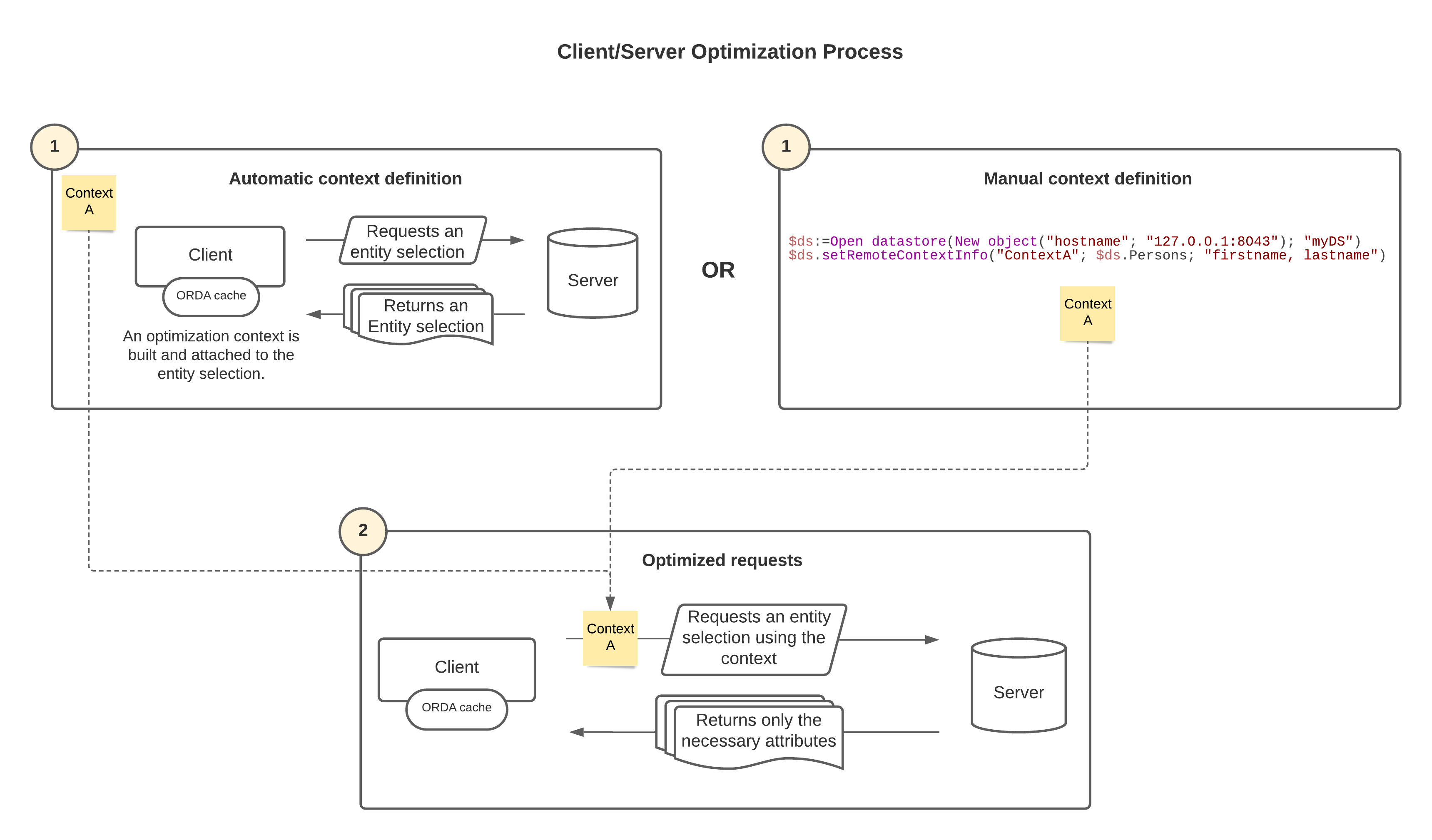
Open datastore で確立された接続で扱われるコンテキストは、メジャーバージョンが共通する 4D でのみ使用できます。 たとえば、4D 20.x リモートアプリケーションは、4D Server 20.x のデータストアのコンテキストのみを使用できます。 たとえば、4D 20.x リモートアプリケーションは、4D Server 20.x のデータストアのコンテキストのみを使用できます。
例題
以下のようなコードがあるとき:
$sel:=$ds.Employee.query("firstname = ab@")
For each($e;$sel)
$s:=$e.firstname+" "+$e.lastname+" works for "+$e.employer.name // $e.employer は Company テーブルを参照します
End for each
最適化機構のおかげでこのリクエストは、ループの 2回目の繰り返しより、$sel の中で実際に使用されている属性 (firstname, lastname, employer, employer.name) のデータのみを取得するようになります。
contextプロパティの使用
context プロパティを使用することで、最適化の利点をさらに増幅させることができます。 このプロパティは、あるエンティティセレクション用に "学習した" 最適化コンテキストを参照します。 これを新しいエンティティセレクションを返す ORDA関数に引数として渡すことで、その返されたエンティティセレクションでは学習フェーズを最初から省略して使用される属性をサーバーにリクエストできるようになります。
.setRemoteContextInfo()関数を使って、コンテキストを作成することもできます。
エンティティセレクションを扱うすべての ORDA関数は、context プロパティをサポートします (たとえば dataClass.query( ) あるいは dataClass.all( ) など)。 エンティティセレクションを扱うすべての ORDA関数は、context プロパティをサポートします (たとえば dataClass.query( ) あるいは dataClass.all( ) など)。 同じ最適化 context プロパティは、同じデータクラスのエンティティセレクションに対してであればどのエンティティセレクションにも渡すことができます。 ただし、 コードの他の部分で新しい属性が使用された際にはコンテキストは自動的に更新されるという点に注意してください。 同じコンテキストを異なるコードで再利用しすぎると、コンテキストを読み込み過ぎて、結果として効率が落ちる可能性があります。 ただし、 コードの他の部分で新しい属性が使用された際にはコンテキストは自動的に更新されるという点に注意してください。 同じコンテキストを異なるコードで再利用しすぎると、コンテキストを読み込み過ぎて、結果として効率が落ちる可能性があります。
同様の機構は読み込まれたエンティティにも実装されており、それによって使用した属性のみがリクエストされるようになります (
dataClass.get( )関数参照)。
dataClass.query( ) を使用した例:
var $sel1; $sel2; $sel3; $sel4; $querysettings; $querysettings2 : Object
var $data : Collection
$querysettings:=New object("context";"shortList")
$querysettings2:=New object("context";"longList")
$sel1:=ds.Employee.query("lastname = S@";$querysettings)
$data:=extractData($sel1) // extractData メソッド内で最適化がトリガーされ、
// コンテキスト "shortList" に紐づけられます
$sel2:=ds.Employee.query("lastname = Sm@";$querysettings)
$data:=extractData($sel2) // extractData メソッド内で最適化がトリガーされ、
// コンテキスト "shortList" に紐づけられます
$sel3:=ds.Employee.query("lastname = Smith";$querysettings2)
$data:=extractDetailedData($sel3) // extractDetailedData メソッド内で最適化がトリガーされ、
// コンテキスト "longList" に紐づけられます
$sel4:=ds.Employee.query("lastname = Brown";$querysettings2)
$data:=extractDetailedData($sel4) // extractDetailedData メソッド内で最適化がトリガーされ、
// コンテキスト "longList" に紐づけられます
エンティティセレクション型リストボックス
4D クライアント/サーバーデスクトップアプリケーションでのエンティティセレクション型リストボックスにおいては、そのコンテンツを表示またはスクロールする際に、最適化が自動的に適用されます。 つまり、リストボックスに表示されている属性のみがサーバーにリクエストされます。
また、リストボックスの カレントの項目 プロパティ式 (コレクション/エンティティセレクション型リストボックス 参照) を介してカレントエンティティをロードする場合には、専用の "ページモード" コンテキストが提供されます。 これによって、"ページ" が追加属性をリクエストしても、リストボックスのコンテキストのオーバーロードが避けられます。 なお、ページコンテキストの生成/使用は カレントの項目 式を使用した場合に限ります (たとえば、entitySelection[index] を介して同じエンティティにアクセスした場合は、エンティティセレクションコンテキストが変化します)。 これによって、"ページ" が追加属性をリクエストしても、リストボックスのコンテキストのオーバーロードが避けられます。 なお、ページコンテキストの生成/使用は カレントの項目 式を使用した場合に限ります (たとえば、entitySelection[index] を介して同じエンティティにアクセスした場合は、エンティティセレクションコンテキストが変化します)。
その後、エンティティを走査する関数がサーバーに送信するリクエストにも、同じ最適化が適用されます。 以下の関数は、ソースエンティティの最適化コンテキストを、戻り値のエンティティに自動的に付与します:
たとえば、次のコードは選択したエンティティをロードし、所属しているエンティティセレクションを走査します。 エンティティは独自のコンテキストにロードされ、リストボックスのコンテキストは影響されません:
$myEntity:=Form.currentElement // カレント項目の式
//... なんらかの処理
$myEntity:=$myEntity.next() // 次のエンティティも同じコンテキストを使用してロードされます
コンテキストの事前設定
最高のパフォーマンスを得るには、アプリケーションの機能またはアルゴリズムごとに最適化コンテキストが定義されていることが推奨されます。 たとえば、あるコンテキストは顧客に関するクエリに、別のコンテキストは商品に関するクエリに使用することができます。
最高レベルに最適化された最終アプリケーションを提供したい場合、以下の手順でコンテキストを事前に設定することで、学習フェーズを省略することができます:
- アルゴリズムを設計します。
- アプリケーションを実行し、自動学習メカニズムに最適化コンテキストを作成させます。
dataStore.getRemoteContextInfo()またはdataStore.getAllRemoteContexts()関数を呼び出して、コンテキストを収集します。entitySelection.getRemoteContextAttributes()とentity.getRemoteContextAttributes()関数を使用して、アルゴリズムがどのように属性を使用するかを分析することができます。entitySelection.getRemoteContextAttributes()とentity.getRemoteContextAttributes()関数を使用して、アルゴリズムがどのように属性を使用するかを分析することができます。- 最後に、アプリケーション起動時に
dataStore.setRemoteContextInfo()関数を呼び出してコンテキストを構築し、これらをアルゴリズムで使用します。
ORDAキャッシュ
最適化のため、ORDA経由でサーバーにリクエストしたデータは、(4Dキャッシュとは異なる) ORDAリモートキャッシュに読み込まれます。 ORDAキャッシュはデータクラスごとに構成され、30秒後に失効します。
キャッシュに含まれるデータは、タイムアウトに達すると期限切れとみなされます。 期限切れデータにアクセスする場合は、サーバーにリクエストが送信されます。 期限切れデータは、スペースが必要になるまでキャッシュに残ります。
refresh() 関数を使用して、ORDAキャッシュにあるエンティティセレクションのデータをいつでも強制的に期限切れにすることができます。
デフォルトでは、ORDAキャッシュは 4D によって透過的に処理されます。 しかし、以下の ORDAクラスの関数を使用して、その内容を制御することができます:
local キーワードの使用
デフォルトで、ORDA データモデル関数 はサーバー上で実行されます。これは関数リクエストと結果のみがネットワーク越しで送信されるため、一般的にはベストパフォーマンスを提供するとされています。 しかしながら、関数がローカルキャッシュ内に既にあるデータを処理するために、クライアント側だけで完全に完結可能な場合もあります。 この場合、関数定義内で local キーワードを使用する ことによって、サーバーへのリクエスト回数をおさえ、結果としてアプリケーションのパフォーマンスを改善することができます。 しかしながら、関数がローカルキャッシュ内に既にあるデータを処理するために、クライアント側だけで完全に完結可能な場合もあります。 この場合、関数定義内で local キーワードを使用する ことによって、サーバーへのリクエスト回数をおさえ、結果としてアプリケーションのパフォーマンスを改善することができます。
最終的にサーバーへのアクセスが必要になっても (ORDAキャッシュが有効期限切れになった場合など) 関数は動作します。 もっとも、それではローカル実行によるパフォーマンスの向上は見込めないため、ローカル関数がサーバー上のデータにアクセスしないことを確認しておくことが推奨されます。 サーバーに対して複数のリクエストをおこなうローカル関数は、サーバー上で実行されて結果だけを返す関数よりも非効率的です。 たとえば、Schools Entityクラスの次の関数を考えます:
// 最も若い生徒を取得する
// local キーワードの不適切な使用例
local Function getYoungest() : Object
return This.students.query("birthDate >= :1"; !2000-01-01!).orderBy("birthDate desc").slice(0; 5)
localキーワードを 使わない 場合、1つのリクエストで結果が得られます。localキーワードを 使う 場合、4つのリクエストが必要になります: Schools エンティティの students エンティティセレクションの取得、query()の実行、orderBy()の実行、slice()の実行。 この例では、localキーワードを使用するのは適切ではありません。 この例では、localキーワードを使用するのは適切ではありません。
例: 属性のチェック
クライアントにロードされ、ユーザーによって更新されたエンティティの属性について、サーバーへ保存リクエストを出すまえに、それらの一貫性を検査します。
StudentsEntity クラスのローカル関数 checkData() は生徒の年齢をチェックします:
Class extends Entity
local Function checkData() -> $status : Object
$status:=New object("success"; True)
Case of
: (This.age()=Null)
$status.success:=False
$status.statusText:="The birthdate is missing"
:((This.age() <15) | (This.age()>30) )
$status.success:=False
$status.statusText:="The student must be between 15 and 30 - This one is "+String(This.age())
End case
呼び出し元のコード:
var $status : Object
// Form.student は全属性とともにロードされており、フォーム上で更新されました
$status:=Form.student.checkData()
If ($status.success)
$status:=Form.student.save() // サーバーを呼び出します
End if