リモートデータストア
リモートデータストア とは、ローカルの 4Dアプリケーション (4D または4D Server) 上で使用される、別の 4Dアプリケーションの データストア への参照です。
ローカルの 4Dアプリケーションは、Open datastore コマンドを呼び出すことで、リモートデータストアに接続し参照します。
リモートマシン上で、4D は セッション を開いて、Open datastore を呼び出したアプリケーションからのリクエストを処理します。 リクエストは内部で REST API を使用し、これには 利用可能なライセンス が必要な場合があります。
Webセッションの使用
Open datastore コマンドによって参照されるリモートデータストアの場合、リクエスト元プロセスとの接続はリモートマシン上では Webセッション により管理されます。
リモートデータストア上で作成される Webセッションは内部的にセッションID によって識別され、4Dアプリケーション上では localID と紐づいています。 データ、エンティティセレクション、エンティティへのアクセスはこのセッションによって自動��的に管理されます。
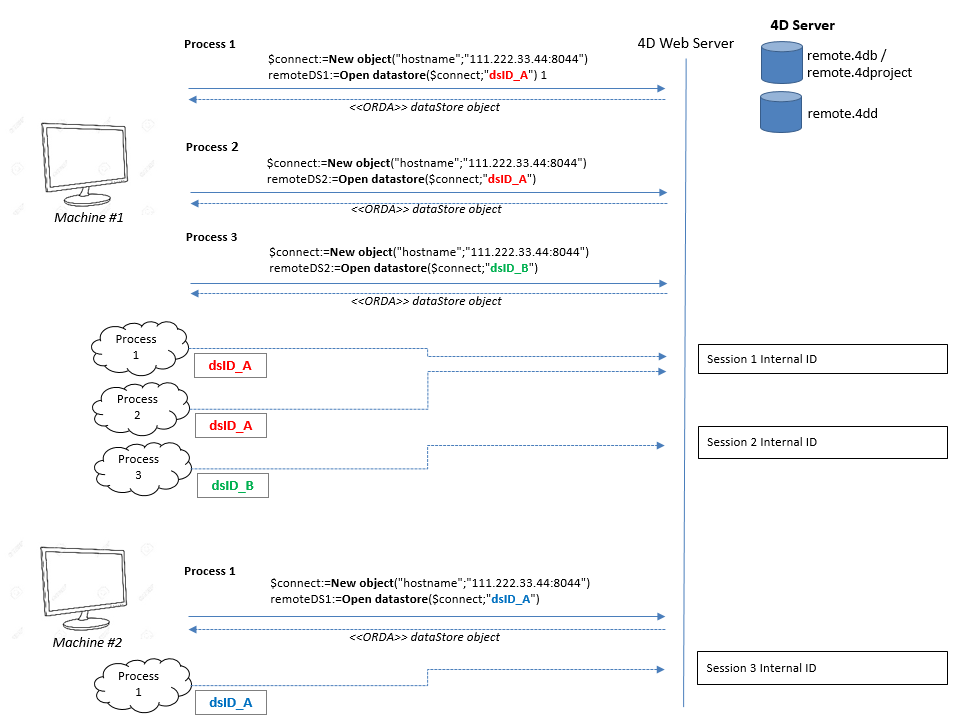
localID はリモートデータストアに接続しているマシンにおけるローカルな識別IDです:
- 同じアプリケーションの別プロセスが同じリモートデータストアに接続する場合、
localIDとセッションは共有することができます。 - 同じアプリケーションの別プロセスが別の
localIDを使って同じデータストアに接続した場合、リモートデータストアでは新しいセッションが開始されます。 - 他のマシンが同じ
localIDを使って同じデータストアに接続した場合、新しいセッションが新しい cookie で開始されます。
これらの原則を下図に示します:
セッションの監視
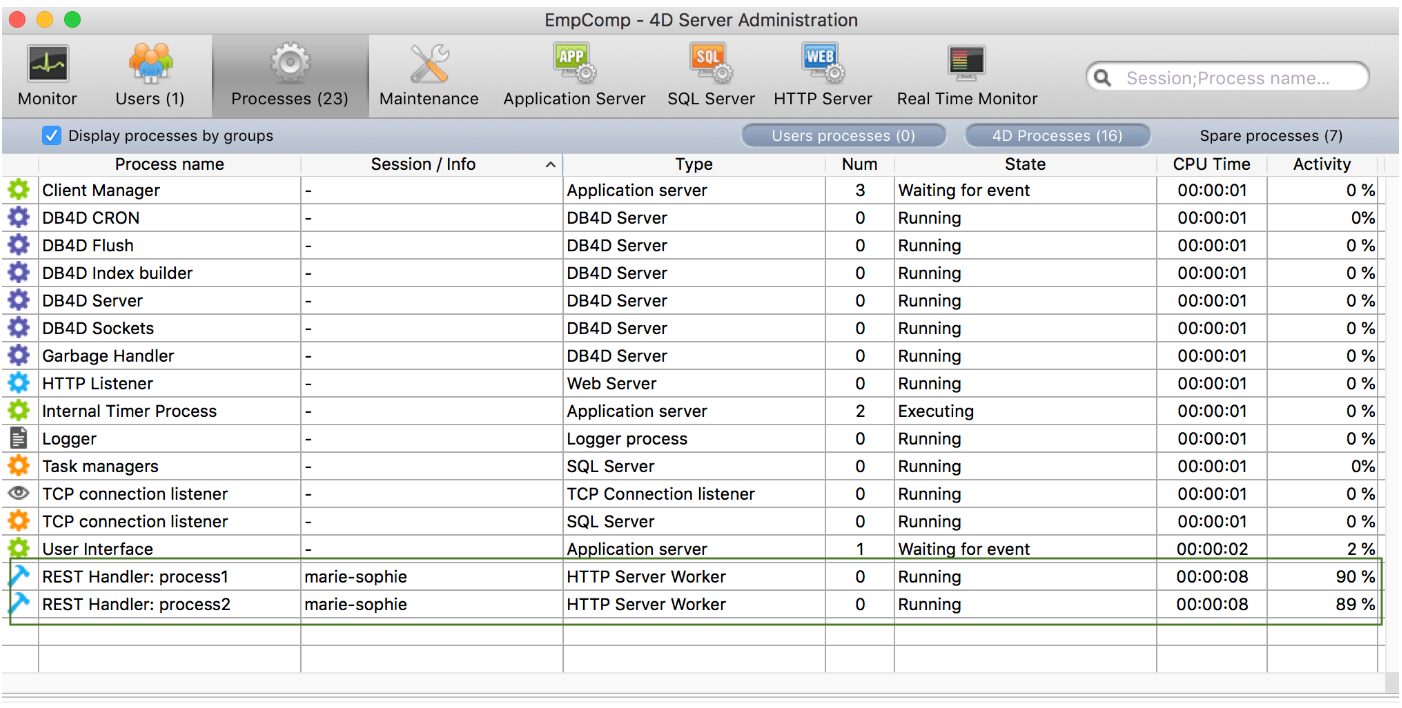
データストアアクセスを管理しているセッションは 4D Server の管理ウィンドウに表示されます:
- プロセス名: "REST Handler: \<process name>"
- タイプ: HTTP Server Worker
- セッション:
Open datastoreコマンドに渡されたユーザー名
次の例では、1つのセッション上で 2つのプロセスが実行中です:
セッションの終了
セッションの有効期限 の段落で説明されているように、アクティビティなしにタイムアウト時間が経過すると、4D は自動的にセッションを終了します。 デフォルトのタイムアウト時間は 60分です。 Open datastore コマンドの connectionInfo パラメーターを指定して、タイムアウト時間を変更することができます。
セッション終了後にリクエストがリモートデータストアに送信された場合、セッションは可能な限り (ライセンスがあり、サーバーが停止していない、など) 再開されます。 ただしセッションが再開しても、ロックやトランザクションに関わるコンテキストは失われていることに留意が必要です (後述参照)。
ロッキングとトランザクション
エンティティロッキングやトランザクションに関連した ORDA 機能は、ORDA のクライアント / サーバーモードと同様に、リモートデータストアにおいてもプロセスレベルで管理されます:
- あるプロセスがリモートデータストアのエンティティをロックした場合、セッションの共有如何に関わらず、他のすべてのプロセスに対してそのエンティティはロックされた状態です (エンティティロッキング 参照)。 同一のレコードに対応する複数のエンティティが 1つのプロセスによってロックされている場合、同プロセス内でそれらがすべてアンロックされないと、ロックは解除されません。 なお、ロックされたエンティティに対する参照がメモリ上に存在しなくなった場合にも、ロックは解除されます。
- トランザクションは
dataStore.startTransaction( )、dataStore.cancelTransaction( )、dataStore.validateTransaction( )のメソッドを使って、リモートデータストアごとに個別に開始・認証・キャンセルすることができます。 これらの操作は他のデータストアには影響しません。 - 従来の 4Dランゲージコマンド (
START TRANSACTION,VALIDATE TRANSACTION,CANCEL TRANSACTION) はdsで返されるメインデータストアに対してのみ動作します。 リモートデータストアのエンティティがあるプロセスのトランザクションで使われている場合、セッションの共有如何に関わらず、他のすべてのプロセスはそのエンティティを更新できません。 - 次の場合にエンティティのロックは解除され、トランザクションはキャンセルされます:
- プロセスが強制終了された
- サーバー上でセッションが閉じられた
- サーバー管理ウィンドウからセッションが強制終了された